利用工具分析Leader节点
进行dump
1、按照文档dump https://developer.hashicorp.com/consul/commands/debug
命令: consul debug -interval=5s -duration=30s -capture agent
2、使用可视化工具查看
需要安装golang,安装Graphviz,这里不多做赘述。
命令:go tool pprof profile.prof
输入:web
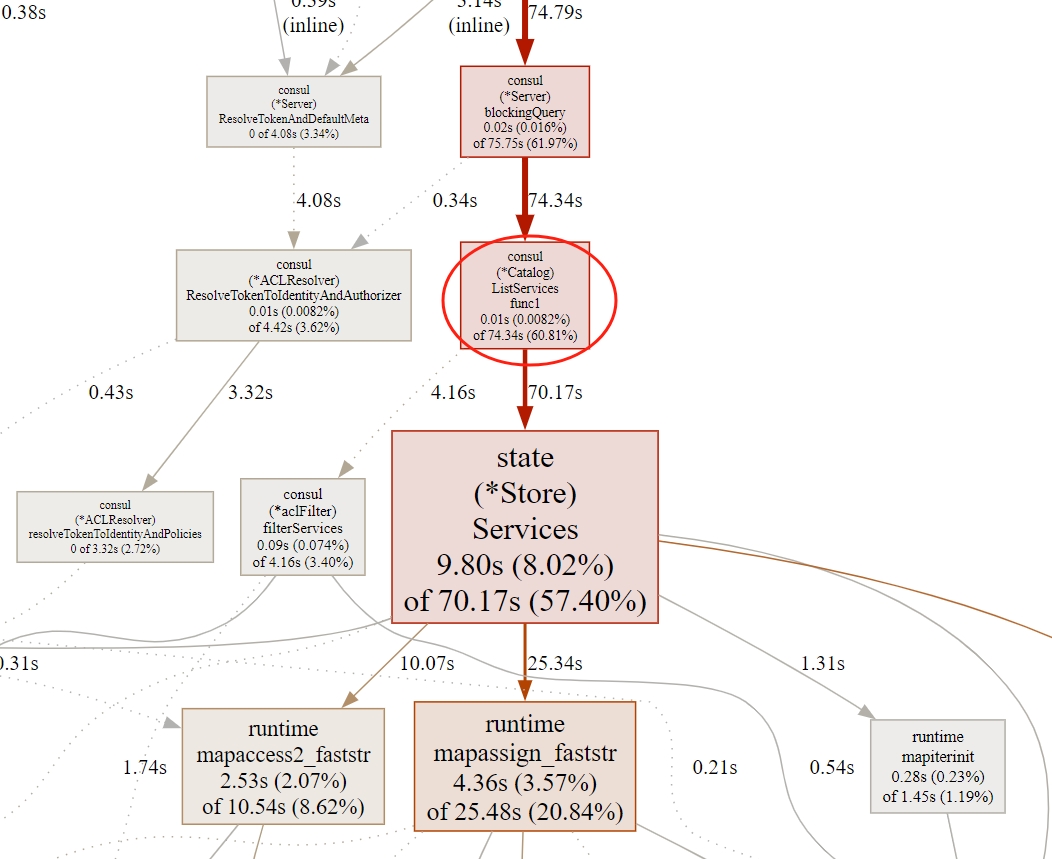
分析原因
从上述pprof分析结果可以看出,大部分Cpu时间都耗费在处理ListService请求上。这个都是spring-cloud-consul客户端发出的健康检查的请求。
另外一个原因是,虚拟机注册上来的服务,存在重复注册的实例信息。同一个服务实例,可能存在多份注册信息,这就导致本该只进行1次的监控检查,会进行多次。
第1点,健康检查接口
/actuator/health 接口为应用默认的健康检查接口。由spring-boot-starter-actuator.jar支持该功能。
如下配置项可以返回健康检查详细的内容(如下截图):
management.endpoint.health.show-details=always
客户端有3处调用Consul的api
客户端对Consul api的访问,都采用了default的一致性参数,是强一致性的要求。该参数表示每次请求都需要从leader读取最新的数据。
该一致性要求会造成一定的性能损失。
1、consul集群(默认开启)
访问的Consul api:包括leader状态,已注册services(2次consul leader访问)
相关代码: ConsulHealthIndicator
配置项:management.health.consul.enabled=true
默认每隔10s,Consul client调用1次/actuator/health接口,返回内容如下。包含了2次Consul leader的请求。

2、服务发现客户端(默认开启)
访问的Consul api:包括leader状态,已注册services(2次consul leader访问)
相关代码:DiscoveryClientHealthIndicator, ConditionalOnDiscoveryHealthIndicatorEnabled
配置项:spring.cloud.discovery.client.health-indicator.enabled=true
默认每隔10s,Consul client调用1次/actuator/health接口,返回内容如下。包含了2次Consul leader的请求。

上述两个配置都是调用Consul获取leader状态和service列表,默认都开启。每次Consul client检查服务的健康状态,就会产生对集群leader的4次访问。
3、ConsulCatalogWatch (默认开启)
访问的Consul api:已注册services
相关代码:ConsulCatalogWatch
配置项:spring.cloud.consul.discovery.catalog-services-watch-delay=1000 #默认每秒执行一次
spring.cloud.consul.discovery.catalog-services-watch.enabled=false #开关
该组件的功能为,每秒读取一次当前的服务列表。然后通过如下代码,广播一个心跳事件。目前我在客户端代码中没有发现接收该事件的处理代码。所以关闭该功能也是安全的。
this.publisher.publishEvent(new HeartbeatEvent(this, consulIndex));
优化建议
这3个功能点,我认为是不必要的。Consul健康检查,应该是对服务本身健康进行检查,而不是要对Consul集群进行检查。
所以建议推广如下配置,减少consul集群压力
management.health.consul.enabled=false
spring.cloud.discovery.client.health-indicator.enabled=false
spring.cloud.consul.discovery.catalog-services-watch.enabled=false
如果有重复注册的服务实例,需要注意去除这些重复的实例。相同ip的实例信息,只需要保留一个即可。