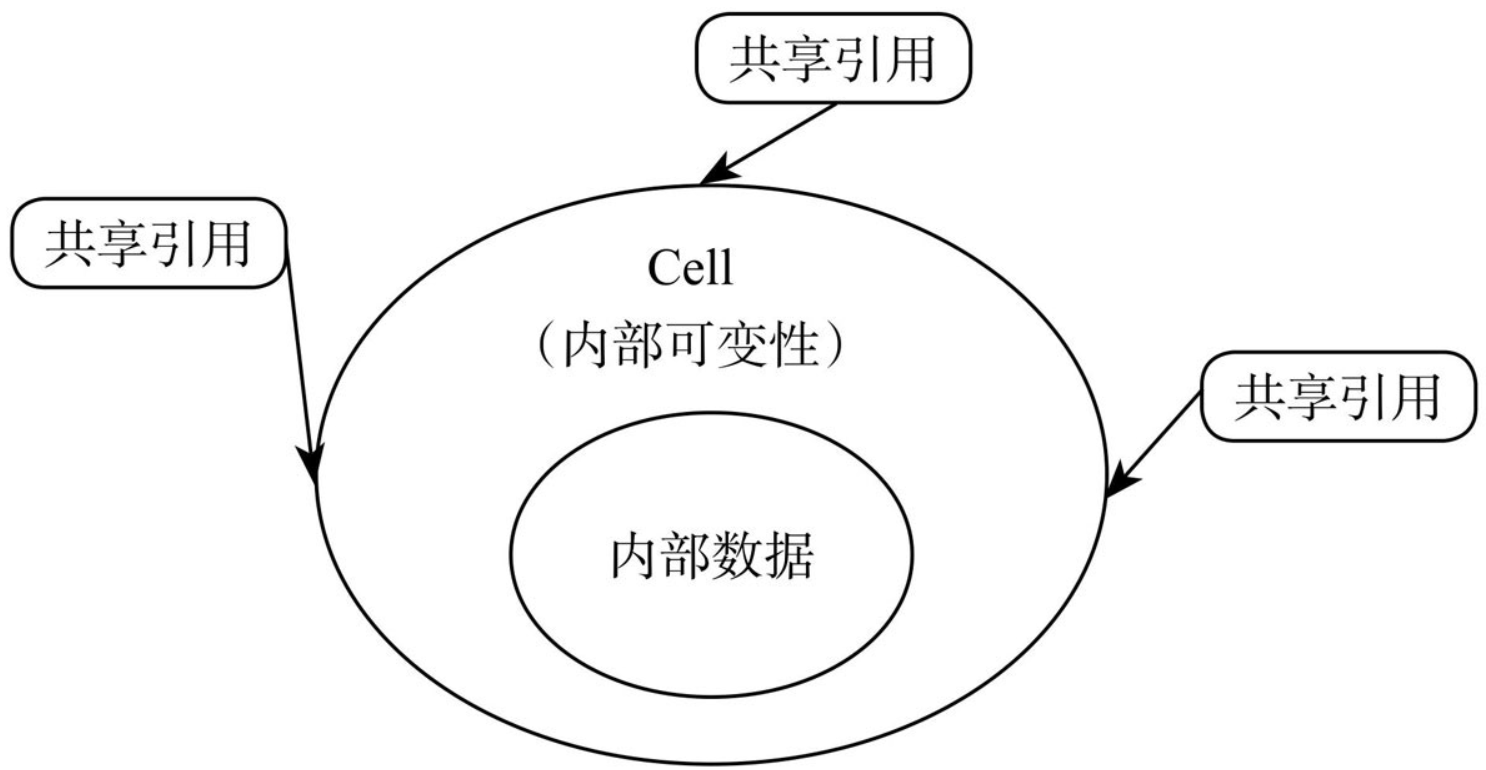
Cell
1 | use std::cell::Cell; |
这次编译通过,执行,结果是符合我们的预期的:
10
Cell { value: 20 }
这里虽然变量都没用mut去声明,但是通过set函数改变了内部值。所谓的内部可变性。
Nacos用户方发来一个问题,说是压测过程中,半夜发现服务掉线了。然后给了我一些日志
1 | 2025-11-05 02:03:58.342 WARN [com.alibaba.nacos.client.naming.grpc.redo.0:c.a.n.c.naming] Grpc Connection is disconnect, skip current redo task |
联想到Nacos(2.0.4)存在服务断线重连机制,所以怀疑该机制失效。找到源码所在位置:
NamingGrpcRedoService
1 | public NamingGrpcRedoService(NamingGrpcClientProxy clientProxy) { |
RedoScheduledTask
1 | @Override |
两个概念:
共享不可变,可变不共享
通过不同的Path访问同一块内存p, *p1, * p2,所以它们存在“共享”。而且它们都只有只读的权限,所以它们存在“共享”,不存在“可变”。因此它一定是安全的。
fn main() {//正常
let i = 0;
let p1 = & i;
let p2 = & i;
println! ("{} {} {}", i, p1, p2);
}
在存在只读借用的情况下,变量绑定i和p1已经互为alias,它们之间存在“共享”,因此必须避免“可变”。这段代码违反了“共享不可变”的原则。
fn main() {//报错
let mut i = 0;
let p1 = & i;
i = 1;
}
因为这段代码中不存在“共享”。在可变借用存在的时候,编译器认为原来的变量绑定i已经被冻结(frozen),不可通过i读写变量。此时有且仅有p1这一个入口可以读写变量。
fn main() {//正常
let mut i = 0;
let p1 = &mut i;
*p1 = 1;
}
因为p1、p2都是可变借用,它们都指向了同一个变量,而且都有修改权限,这是Rust不允许的情况,因此这段代码无法编译通过。
fn main() {//报错
let mut i = 0;
let p1 = &mut i;
let p2 = &mut i;
}
&mut型借用也经常被称为“独占指针”, &型借用也经常被称为“共享指针”。
先看一个示例
1 | fn main() { |
变量对其管理的内存拥有所有权。这个所有权不仅可以被转移(move),还可以被借用(borrow)。
借用指针的语法使用
借用指针与普通指针的内部数据是一模一样的,唯一的区别是语义层面上的。它的作用是告诉编译器,它对指向的这块内存区域没有所有权。
1 | fn main() { |
借用指针在编译后,实际上就是一个普通的指针,它的意义只能在编译阶段的静态检查中体现。
“所有权”代表着以下意义:
每个值在Rust中都有一个变量来管理它,这个变量就是这个值、这块内存的所有者;
每个值在一个时间点上只有一个管理者;
当变量所在的作用域结束的时候,变量以及它代表的值将会被销毁。
一个变量可以把它拥有的值转移给另外一个变量,称为“所有权转移”。赋值语句、函数调用、函数返回等,都有可能导致所有权转移。
1 | fn create() -> String { |
所有权转移的步骤分解如下。
main函数调用create函数。
在调用create函数的时候创建了字符串,在栈上和堆上都分配有内存。局部变量s是这些内存的所有者。
create函数返回的时候,需要将局部变量s移动到函数外面,这个过程就是简单地按字节复制memcpy。
同理,在调用consume函数的时候,需要将main函数中的局部变量转移到consume函数,这个过程也是简单地按字节复制memcpy。
当consume函数结束的时候,它并没有把内部的局部变量再转移出来,这种情况下,consume内部局部变量的生命周期就该结束了。这个局部变量s生命周期结束的时候,会自动释放它所拥有的内存,因此字符串也就被释放了。
Rust中所有权转移的重要特点是,它是所有类型的默认语义。这是许多读者一开始不习惯的地方。这里再重复一遍,请大家牢牢记住,Rust中的变量绑定操作,默认是move语义,执行了新的变量绑定后,原来的变量就不能再被使用!一定要记住!
两种方式实现自定义宏:
通过标准库提供的macro_rules!宏实现
通过提供编译器扩展来实现
编译器扩展只能在不稳定版本中使用。它的API正在重新设计中,还没有正式定稿,这就是所谓的macro 2.0。
实现这样一个宏定义
1 | let counts = hashmap! ['A' => 0, 'C' => 0, 'G' => 0, 'T' => 0]; |
实现了hashmap! {‘A’ => ‘1’}
1 | macro_rules! hashmap { |
我们希望这个宏扩展开后的类型是HashMap,而且进行了合理的初始化,那么我们可以使用“语句块”的方式来实现:
1 | macro_rules! hashmap { |
现在我们希望在宏里面,可以支持重复多个这样的语法元素。我们可以使用+模式和*模式来完成。类似正则表达式的概念,+代表一个或者多个重复,*代表零个或者多个重复。因此,我们需要把需要重复的部分用括号括起来,并加上逗号分隔符:
1 | macro_rules! hashmap { |
最后,我们在语法扩展的部分也使用*符号,将输入部分扩展为多条insert语句。最终的结果如下所示:
1 | macro_rules! hashmap { |
对于一些简单的宏,这种“示例型”(by example)的方式足够使用了。但是更复杂的逻辑则需要通过更复杂的方式来实现,这就是所谓的“过程宏”(procedural macro)。它是直接用Rust语言写出来的,相当于一个编译器插件。但是编译器插件的最大问题是,它依赖于编译器的内部实现方式。一旦编译器内部有所变化,那么对应的宏就有可能出现编译错误,需要修改。因此,Rust中的“宏”一直难以稳定。
1 | let tuple = (1_i32, false, 3f32); |
1 | struct T1 (i32, char); |
1 | enum Direction { |
数组本身所容纳的元素个数也必须是编译期确定的,执行阶段不可变。数组类型的表示方式为[T; n]。其中T代表元素类型;n代表元素个数。
1 | fn main() { |
在Rust中,对于两个数组类型,只有元素类型和元素个数都完全相同,这两个数组才是同类型的。
1 | fn main() { |
把数组xs作为参数传给一个函数,这个数组并不会退化成一个指针。而是会将这个数组完整复制进这个函数。函数体内对数组的改动不会影响到外面的数组。
1 | fn main() { |
数组本身没有实现IntoIterator trait,但是数组切片是实现了的。所以我们可以直接在for in循环中使用数组切片,而不能直接使用数组本身。
1 | fn main() { |
1 | fn main() { |
Slice与普通的指针是不同的,它有一个非常形象的名字:胖指针(fat pointer)。与这个概念相对应的概念是“动态大小类型”(Dynamic Sized Type, DST)。所谓的DST指的是编译阶段无法确定占用空间大小的类型。为了安全性,指向DST的指针一般是胖指针。
1 | trait Shape { |
具有receiver参数的函数,我们称为“方法”(method),可以通过变量实例使用小数点来调用。
没有receiver参数的函数,我们称为“静态函数”(static function),可以通过类型加双冒号::的方式来调用。
Rust中Self(大写S)和self(小写s)都是关键字,大写S的是类型名,小写s的是变量名。
1 | struct Circle { |
另一种写法“内在方法”
1 | impl Circle { |
trait中可以包含方法的默认实现。如果这个方法在trait中已经有了方法体,那么在针对具体类型实现的时候,就可以选择不用重写。
1 | fn add1(t : (i32, i32)) -> i32 { //模式解构 |
会报错,类型不一致。每个函数都有自己得类型。
1 | // 写法一,用 as 类型转换 |
Rust的函数体内也允许定义其他item,包括静态变量、常量、函数、trait、类型、模块等。
1 | fn test_inner() { |
1 | fn diverges() -> ! { |
可以被转换成任意类型